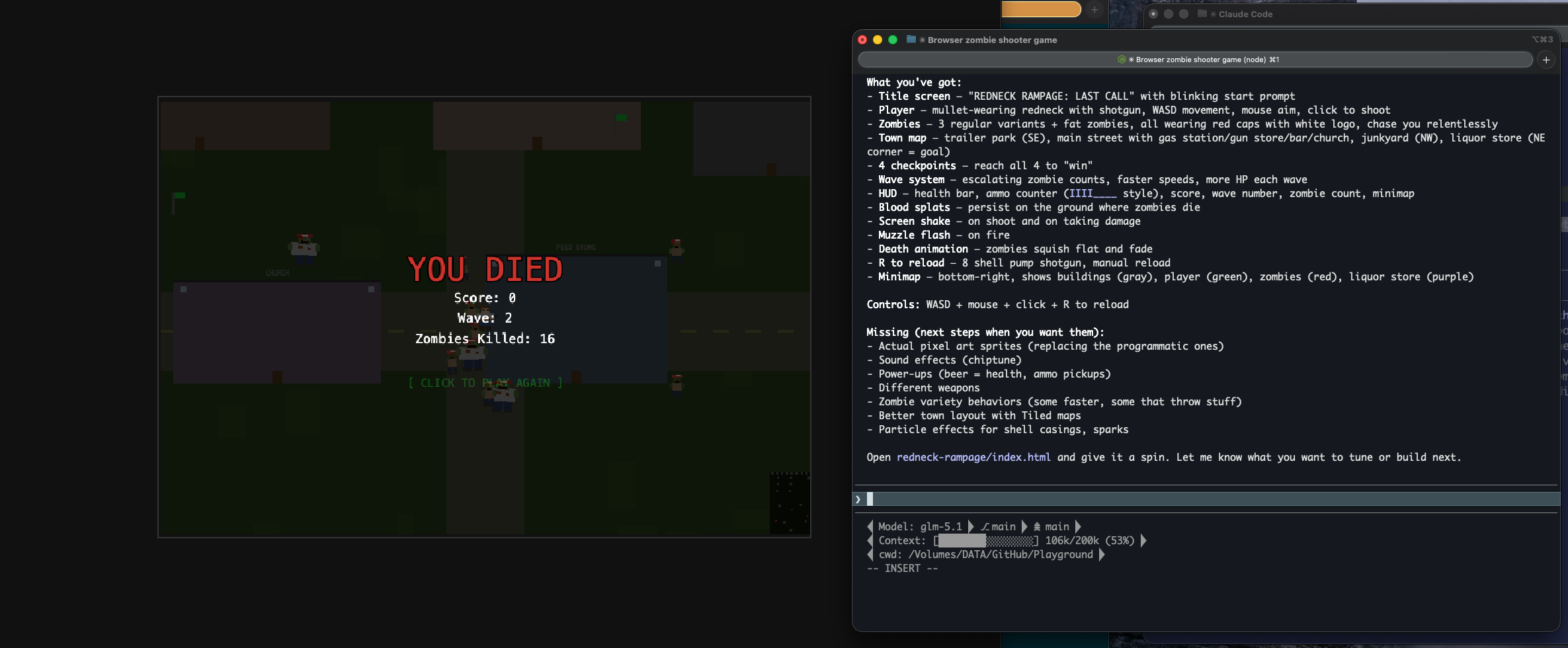
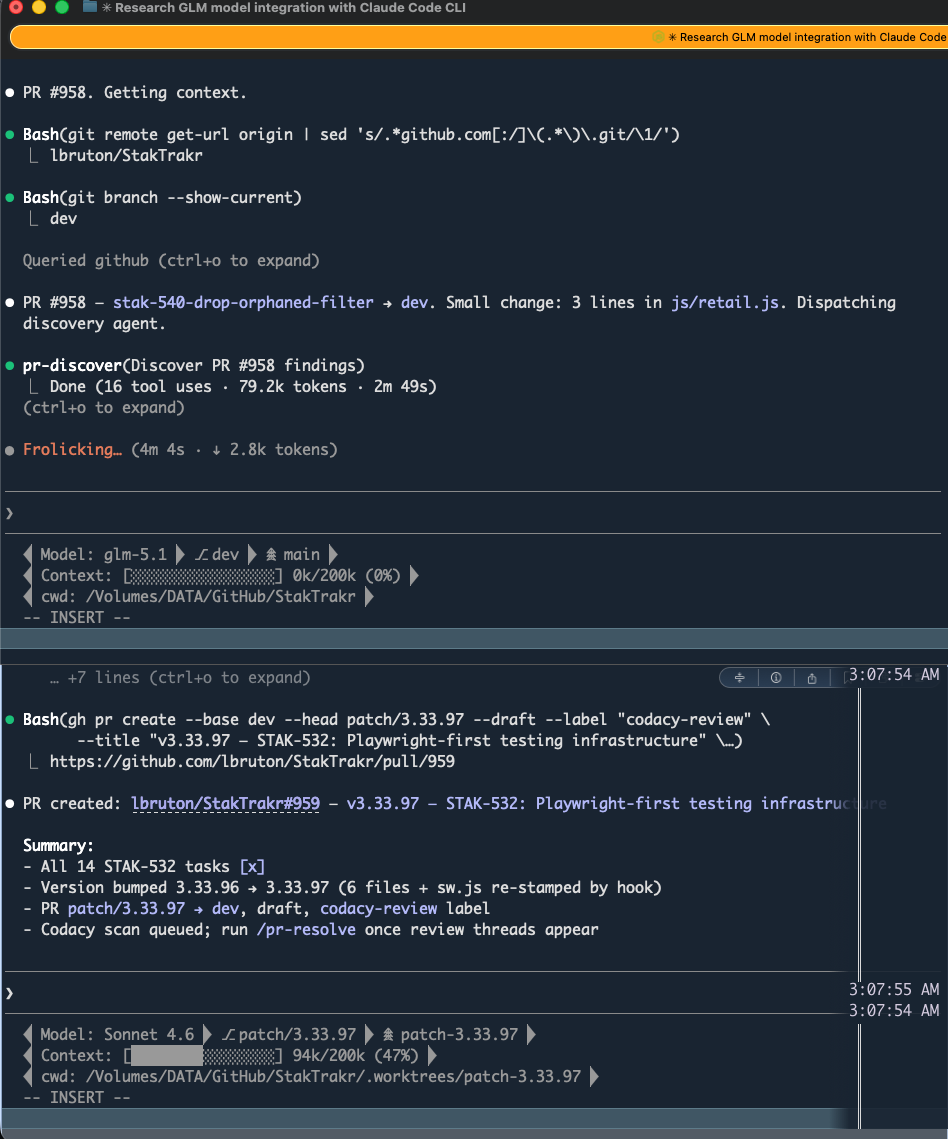
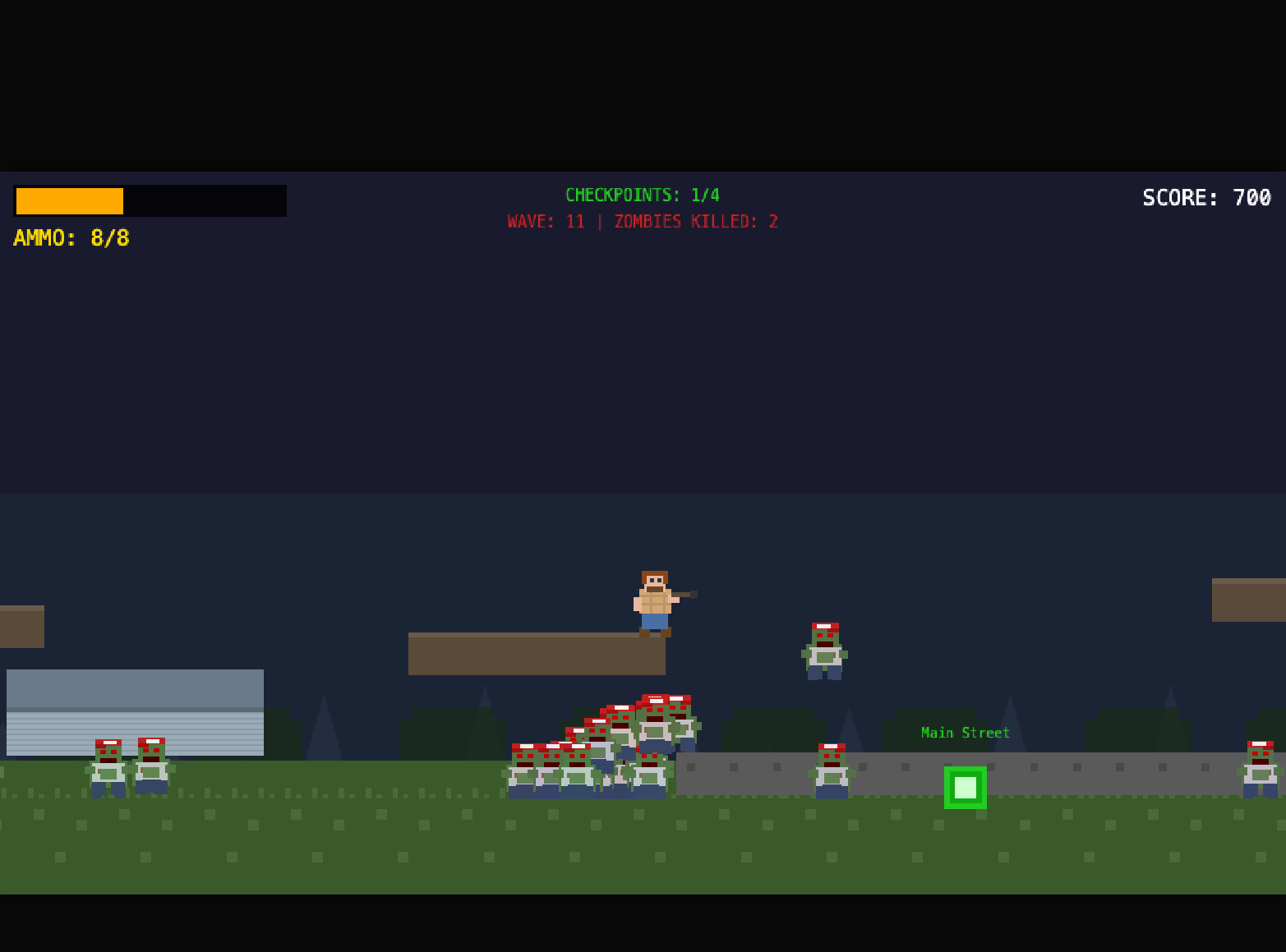
Setup
Shell Aliases — Two Minutes to Multi-Model
Create a file that defines aliases for each backend. Source it from your shell profile so it survives reboots. Each alias launches the same claude binary with different environment variables.
# GLM — GLM-5.1 on opus, GLM-4.7 on sonnet/haiku/subagents
# 200K context, z.ai coding plan
alias claude-glm='ANTHROPIC_BASE_URL="https://api.z.ai/api/anthropic" \
ANTHROPIC_API_KEY="your-glm-api-key" \
ENABLE_TOOL_SEARCH=false \
ANTHROPIC_DEFAULT_OPUS_MODEL="GLM-5.1" \
ANTHROPIC_DEFAULT_SONNET_MODEL="GLM-4.7" \
ANTHROPIC_DEFAULT_HAIKU_MODEL="GLM-4.7" \
ANTHROPIC_DEFAULT_OPUS_MODEL_NAME="GLM-5.1" \
ANTHROPIC_DEFAULT_SONNET_MODEL_NAME="GLM-4.7" \
ANTHROPIC_DEFAULT_HAIKU_MODEL_NAME="GLM-4.7" \
CLAUDE_CODE_SUBAGENT_MODEL="GLM-4.7" \
CLAUDE_CODE_MAX_OUTPUT_TOKENS="32000" \
CLAUDE_CODE_AUTO_COMPACT_WINDOW="180000" \
CLAUDE_CODE_DISABLE_NONESSENTIAL_TRAFFIC="1" \
CLAUDE_CODE_DISABLE_EXPERIMENTAL_BETAS="1" \
API_TIMEOUT_MS="3000000" \
claude'
# Kimi K2.5 (Moonshot) — subscription plan ($30/mo), 262K context
alias claude-kimi='ANTHROPIC_BASE_URL="https://api.kimi.com/coding/" \
ANTHROPIC_API_KEY="your-kimi-api-key" \
ENABLE_TOOL_SEARCH=false \
ANTHROPIC_DEFAULT_OPUS_MODEL="kimi-for-coding" \
ANTHROPIC_DEFAULT_SONNET_MODEL="kimi-for-coding" \
ANTHROPIC_DEFAULT_HAIKU_MODEL="kimi-for-coding" \
ANTHROPIC_DEFAULT_OPUS_MODEL_NAME="Kimi K2.5" \
ANTHROPIC_DEFAULT_SONNET_MODEL_NAME="Kimi K2.5" \
ANTHROPIC_DEFAULT_HAIKU_MODEL_NAME="Kimi K2.5" \
CLAUDE_CODE_SUBAGENT_MODEL="kimi-for-coding" \
CLAUDE_CODE_MAX_OUTPUT_TOKENS="32000" \
CLAUDE_CODE_AUTO_COMPACT_WINDOW="230000" \
CLAUDE_CODE_DISABLE_NONESSENTIAL_TRAFFIC="1" \
CLAUDE_CODE_DISABLE_EXPERIMENTAL_BETAS="1" \
API_TIMEOUT_MS="3000000" \
claude'
# Qwen 3.6 Plus (Alibaba Cloud Coding Plan) — $50/mo, multi-model plan
# Also bundles kimi-k2.5, glm-5, MiniMax-M2.5 under the same API key
alias claude-qwen='ANTHROPIC_BASE_URL="https://coding-intl.dashscope.aliyuncs.com/apps/anthropic" \
ANTHROPIC_API_KEY="your-alibaba-coding-plan-key" \
ENABLE_TOOL_SEARCH=false \
ANTHROPIC_DEFAULT_OPUS_MODEL="qwen3.6-plus" \
ANTHROPIC_DEFAULT_SONNET_MODEL="qwen3.6-plus" \
ANTHROPIC_DEFAULT_HAIKU_MODEL="qwen3.6-plus" \
ANTHROPIC_DEFAULT_OPUS_MODEL_NAME="Qwen 3.6+" \
ANTHROPIC_DEFAULT_SONNET_MODEL_NAME="Qwen 3.6+" \
ANTHROPIC_DEFAULT_HAIKU_MODEL_NAME="Qwen 3.6+" \
CLAUDE_CODE_SUBAGENT_MODEL="qwen3.6-plus" \
CLAUDE_CODE_MAX_OUTPUT_TOKENS="32000" \
CLAUDE_CODE_DISABLE_NONESSENTIAL_TRAFFIC="1" \
CLAUDE_CODE_DISABLE_EXPERIMENTAL_BETAS="1" \
API_TIMEOUT_MS="3000000" \
claude'
Alibaba Coding Plan bundles multiple models
The $50/mo Alibaba Cloud Coding Plan API key (
sk-sp-xxxxx) also works with
kimi-k2.5,
glm-5,
qwen3-coder-plus, and
MiniMax-M2.5. You can use it as an alternative provider for your Kimi or GLM aliases by swapping the base URL to
coding-intl.dashscope.aliyuncs.com/apps/anthropic and the model IDs to their Alibaba-hosted equivalents. One API key, multiple backends.
# Load AI aliases
[ -f "$HOME/.ai-aliases.zsh" ] && source "$HOME/.ai-aliases.zsh"
What the extra env vars do
| Variable | Purpose |
|---|
ENABLE_TOOL_SEARCH=false | Disables deferred tool schema loading. Required for GLM (see token burn note below). Recommended for all non-Anthropic backends. |
CLAUDE_CODE_SUBAGENT_MODEL | Model used for subagent tasks. Without this, subagents may try to use the opus slot model unnecessarily. |
CLAUDE_CODE_MAX_OUTPUT_TOKENS | Cap output tokens per response. Prevents runaway generation on models without native limits. |
CLAUDE_CODE_AUTO_COMPACT_WINDOW | Token count at which auto-compaction triggers. Set below the model's actual context limit to compact before hitting the wall. |
CLAUDE_CODE_DISABLE_NONESSENTIAL_TRAFFIC | Disables telemetry and analytics calls that consume tokens and add latency on non-Anthropic backends. |
CLAUDE_CODE_DISABLE_EXPERIMENTAL_BETAS | Disables experimental features that may not work correctly with non-Anthropic API endpoints. |
Authentication precedence
Claude Code checks credentials in this order: ANTHROPIC_AUTH_TOKEN > ANTHROPIC_API_KEY > OAuth login. Either variable works in your aliases — ANTHROPIC_API_KEY is sufficient and avoids overwriting the OAuth token. You'll see a one-time auth prompt on first launch; approve it and the session uses the API key cleanly.
Shell environment variables always override settings.json. No config file conflicts between backends — your regular claude command keeps using MAX, and each alias overrides cleanly.
First launch
The first time you run a backend alias, Claude Code may ask "Do you want to use this API key?" — say Yes. The choice is remembered for that session. If you see an auth conflict warning, it's safe to proceed — the API key takes precedence.